今天聊的话题依旧和技术有关。做技术的,往往都很擅长使用搜索引擎来去查询资讯,借助搜索到的资料来完成自己的工作,所以又有了 “面向 Google 编程” 和 “面向 StackOverFlow 编程”。不过,搜索引擎不一定就能够找到所有有价值的内容。我们且不说暗网(Dark Web),单纯是我们平时可以浏览到的网页,都未必每个都能被搜索到。
[title]为什么你搜索不到有价值的内容[/title]
搜索引擎的工作机理是基于蜘蛛机器人(Spider)的,蜘蛛机器人顺着你网站上一个又一个的链接,访问到一个又一个的页面,并将内容保存在自己的服务器上,进行分词处理,以便于你的搜索查询。但是,蜘蛛的工作也是依赖于网站的配置文件的,如果网站主在配置文件中写明了,那蜘蛛就不再爬取相关的内容。比如,下图中的淘宝网便是如此。
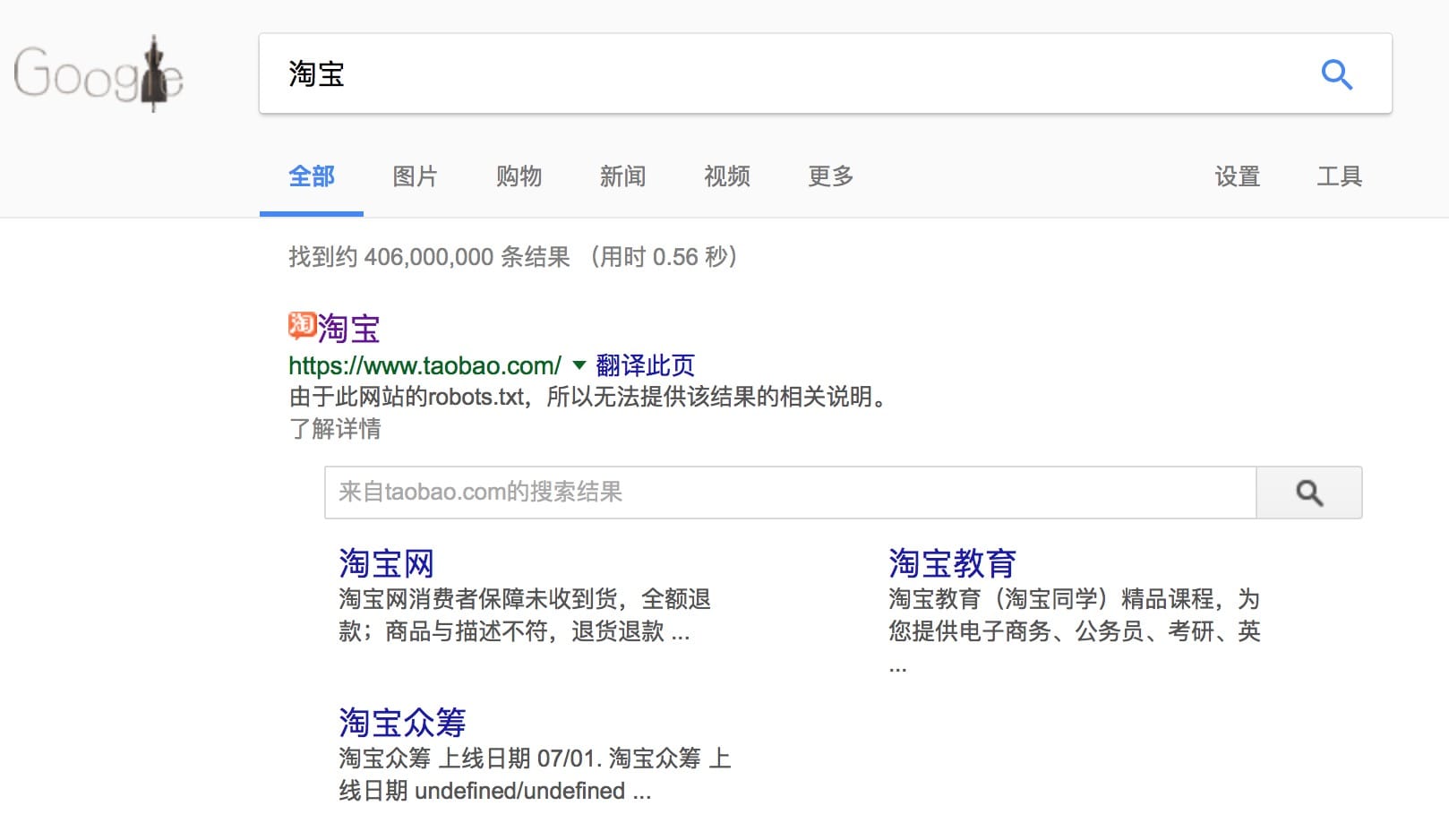
淘宝网当然有非常多的页面,但是在搜索引擎中,你却搜索不到任何关于商品的页面,这便是淘宝网所使用的 robots.txt 定义的。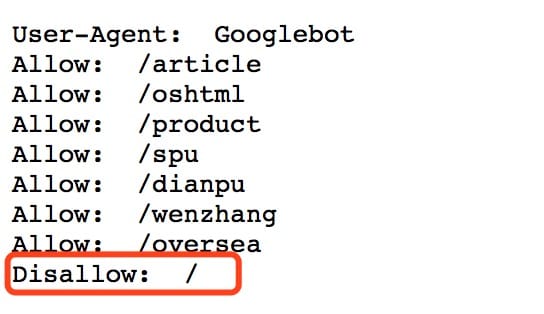
通过 Disallow ,淘宝网保护了自己网站下的详情页面,使得商户们只能针对淘宝自家的搜索工具来进行优化,并购买付费的推广,
[title]IBM 被隐藏起来的东西[/title]
IBM 作为知名的技术解决方案提供商,自然是有其自己的技术交流社区,那就是 IBM developerWorks。
在 developWorks 社区内沉淀了大量的优秀的文章,涵盖了语言、云计算、Linux、IOT、安全、移动开发等多个领域。对于大部分开发者来说,只要 IBM 曾经有人研究过这个方面,那么你就有可能在这里找到你所想要的东西。而且,由于这些文章大多出自 IBM 内部团队,所以质量也普遍较高。当你无法通过搜索引擎找到你想要的东西时,不妨来这里看看。
当然,互联网上隐藏的东西并不少,同样的网站还有 Intel 的 DeveloperZone ,不妨去看看。
被忽视的蓝色巨人 IBM
发表评论