面试题目
- 你熟悉哪些语言,对他们打分多少?
- Vue.js 的一些原理
- 对于队列了解多么
- 函数式编程
- 项目经理
- 十万条数据展示
- 函数节流
由于主域名的备案掉了,所以我不得已,将站点从国内的 VPS 上迁移到了国外的 VPS 上,但是,站点迁移,速度不能下降。
事实上,经过一段优化,目前这个站点的速度着实不错,对我自己来说,基本上是秒开,而在测试网站上,速度也是杠杠的。
除了极个别监测点的速度实在是太慢,绝大多数的监测点都在 1s 内打开。
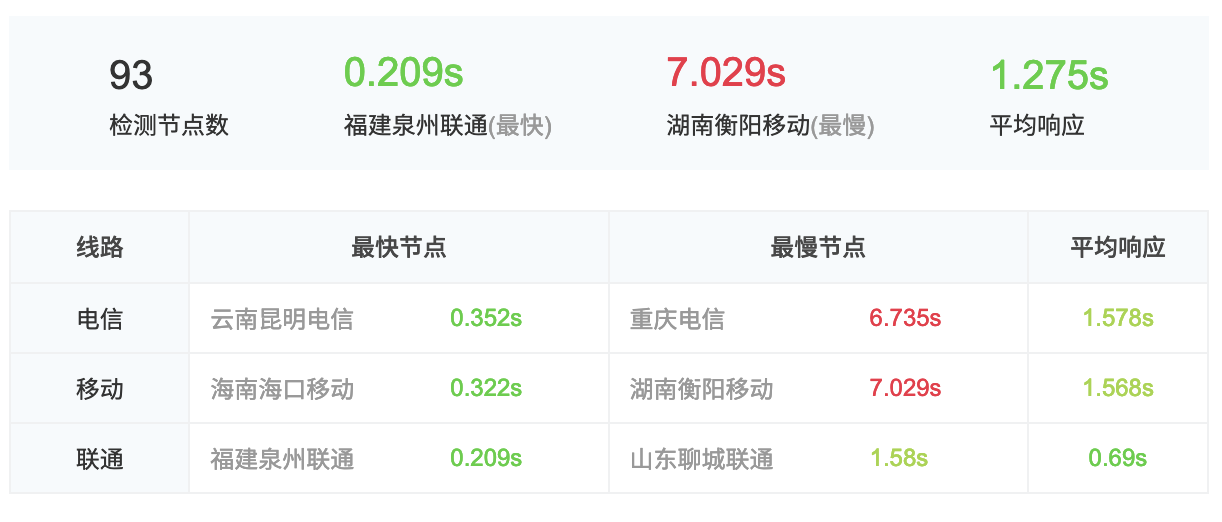
能达到这样的速度,背后意味着很多种优化。我们一一来看。
如果要对网站速度进行优化,就需要理解,在我们从浏览器中输入一个网址,到我们最终网页加载完成,都经历了哪些流程。
当然, 在实际执行过程中,我们需要考虑的不仅仅是这三个点,不过就这三个点而言,也足够我们进行优化了,更加细致的,可以在后续遇见新的性能瓶颈后,进行优化。
在理解了原理后,我们可以一一来分析
对细节进行分析以后,可以看到,我的站点在解析时间上的耗时是普遍比较长的,大多是在 0.3 秒,这是一个优化点。
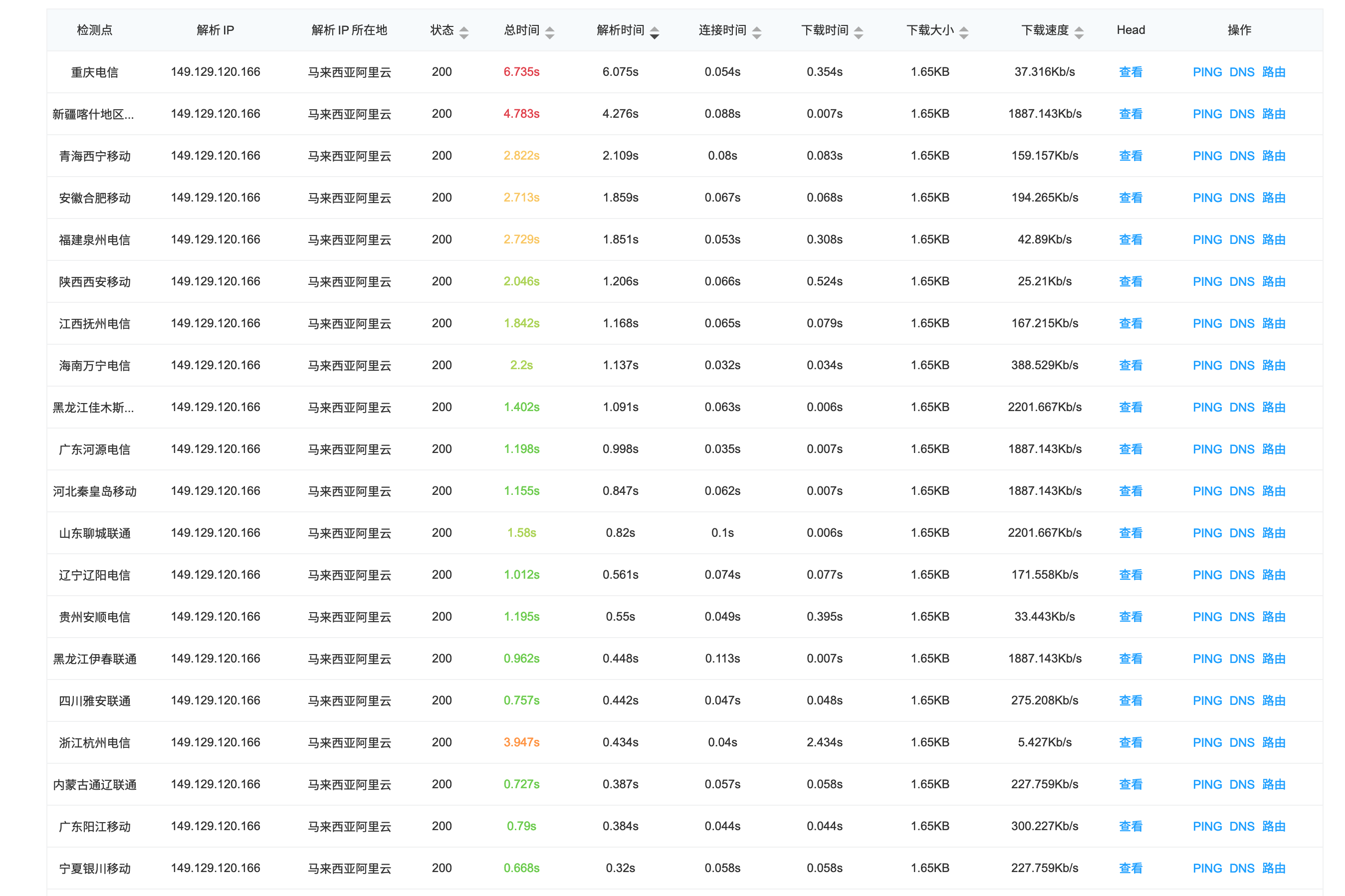
DNS 的优化总的来说,乏善可陈。因为系统底层对于 DNS 的机制只有两处,分别是
如果想要优化,那你就需要降低你的 DNS 解析时间。Hosts 显然是不靠谱的,你不可能让你的用户都去修改了 Hosts 后再使用。
而 DNS 解析,目前我使用的是免费的阿里云 DNS ,这里的优化其实依赖的是阿里云的 DNS 优化(付费版可能会好一点,不过我暂时不考虑上付费 DNS)。
内容下载可以分为两个部分
在内容下载整个流程中,WordPress 主要的问题往往是卡在内容生成方面。
由于 WordPress 的功能强大,且在优化方面做的一般,因此,当我们的 WordPress 的内容足够多的时候, 数据库的查询就会开始变慢。
在这个时候,我们可以选择使用一些工具来加速站点的优化。一般的来说,会考虑使用 Key Value 数据库来替代直接使用 MySQL 进行查询。
这方面可选的包括
我因为懒得配置 MemeCached 和 Redis ,因此使用的是文件缓存,这里我用的是 WordPress 的 WP-Optimize 插件

可以看到,我的站点的缓存数量达到了 2716,缓存的大小达到了 45.6MB。也正是这些缓存,让我的站点在内容计算方面不需要耗费太多的时间,优化站点的体验。
当然,如果你追求更好的速度,可以考虑上 Redis 或 Memcache ,这些内容互联网上有非常多的教程,我就不再一一介绍。
说完了内容生成,来谈一谈内容下载。
在内容下载方面,其实主要受限于你所使用的虚拟主机、VPS、云服务器性能。
在我们购买虚拟主机、云服务器的时候,我们往往会要购买相应的带宽。你购买的带宽越大,你的站点在下载时能够使用的带宽就会越大,相应的,下载的速度也就会越大。
在这方面,如果你的站点有备案,可以考虑购买一些国内的 CDN 服务,使用 CDN 来完成站点的加速,让你的站点加载速度可以变得更快一些。我的域名没有备案,所以没办法使用国内的 CDN,比较遗憾。
内容下载到本地,就会需要进行内容的渲染,而渲染的过程则和你的站点设计、标签数量、复杂度等都有关系。
你会发现,我现在站点使用的大多数是 WordPress 官方的主题,官方的主题的好处在于其站点设计简洁大方,同时页面的标签结构会比较合理,可以确保不会卡在一些奇奇怪怪得地方。
类似的,这也是为什么我很讨厌一些站点生成器(可视化拖拽工具),他们的确可以很方便的生成,但相应的,也会带来大量的冗余标签,让我觉得十分不优雅(当然,背后的人效计算又是另外一回事了)。
对于你自己的博客来说,你也可以参照我的优化方法,来找到自己的问题点,并进行相应的优化,当然,如果你有什么想要讨论的,也欢迎你在下方的留言区和我一起分享。
Append:
我将 DNS 从阿里云免费 DNS 切换到 DNSPod 的个人专业版的以后,我的 DNS 解析时间获得大幅度下降,解析速度降为 0.13s 以内。如果你的解析速度也很高,值得试试。

Vercel 是我自己非常喜欢的平台,我自己的一些项目都会选择使用 Vercel 来部署。比如 Logoly、EasyWPBook 等等。
主要是其在中国大陆的访问速度是比 Netlify 和 Github Pages 更快。但不得不说的是,Vercel 提供了 Production 环境和 Development 环境,对于项目开发时是非常有用的,当你提交一个 commit 或者是一个 PR 时, Vercel 会自动帮你部署,并将相应的 URL comment 到你的 commit 或 PR 下,你只需要点击相应链接,就可以预览效果,十分方便。
但 Vercel 的 Teams 功能是付费的,对于一些 Organization 来说,你需要付费用 Vercel 成本是比较高的。特别是如果你是一个 OpenSource Project,你大概率入不敷出。在这种情况下,如何才能在 Organization Project 中免费使用 Vercel 呢?我考虑了一个绕过去的方法。
我们之所以无法使用在项目中无法免费使用 Vercel 是 Vercel 的产品策略问题。
而我们被禁用的无法使用官方自建的 Github Apps 来部署,但不意味着我们不可以自己实现这样的逻辑,来实现在组织内项目进行push。
而想要达成这样的效果,需要你具备两个条件
而前者,可以通过 Github 提供的 Action 来完成。后者则可以通过编写代码来完成。不过好在,我在 Github 的 Marketplace 中找到了别人已经写好的 Action ,因此又可以少写一些代码(开心?)。
接下来,看看具体要如何操作。
在进行后续的操作之前, 你需要先安装配置过程中的依赖。
执行如下命令安装 Vercel CLI
npm i -g vercel为了正常部署,你需要创建一个项目,并将其 push 到 Github。当然,如果你已经创建好了项目,就直接把项目 Clone 到本地就好。
这一步是为了在 Vercel 上创建一个项目,因为 Vercel 不支持通过网页端创建项目,只支持在 CLI 或通过 Git 接入自动创建。
在你的项目根目录,执行命令 vercel 来触发 Vercel 的部署,它会自动上传你的项目到 Vercel 。如果你之前登录过,会看到类似这样的界面,根据其提示进行配置就好。如果你之前没有登录过,你登录后会出现类似的界面。根据提示进行配置。
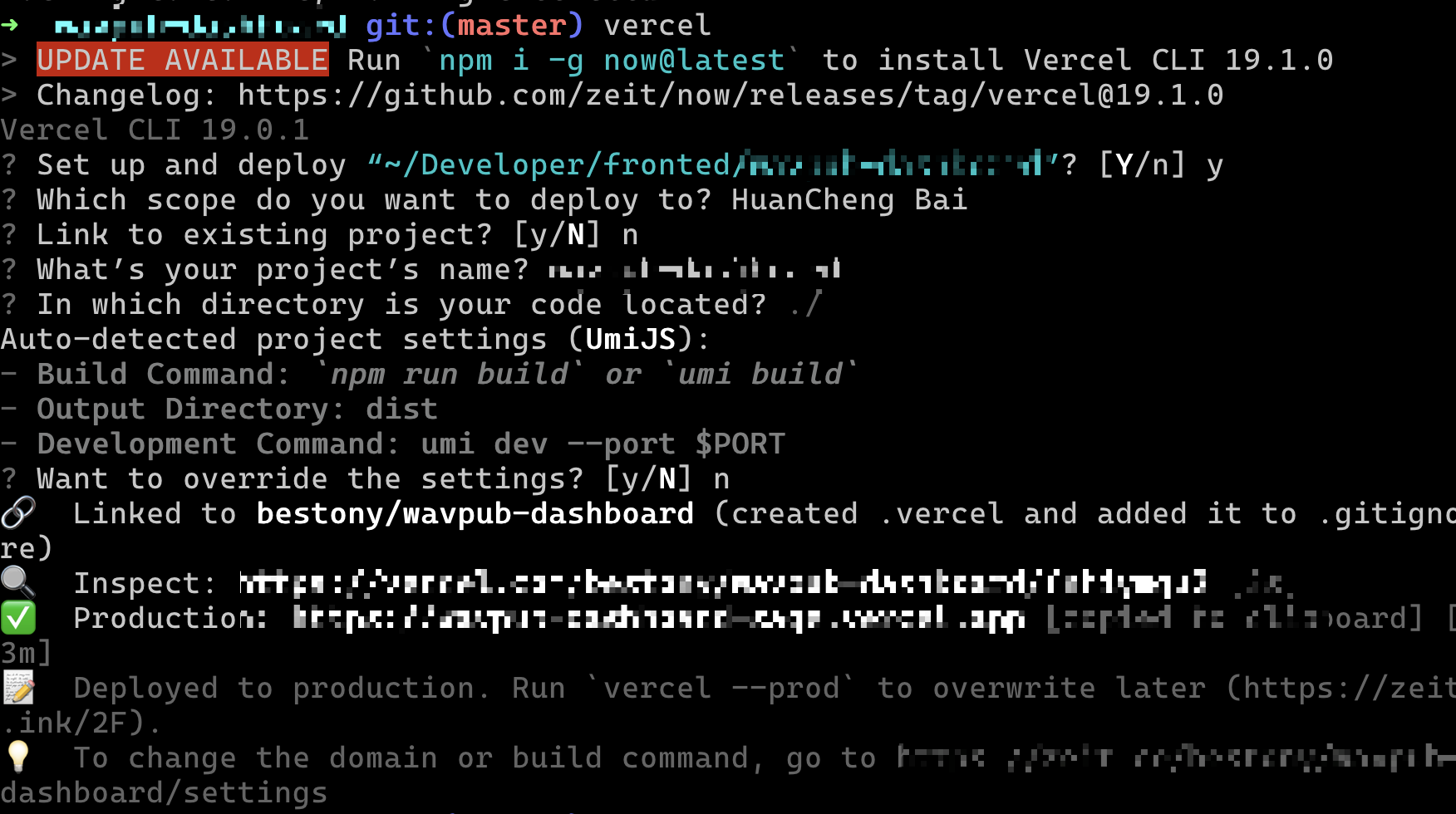
想要部署一个项目到 Vercel ,你需要知道三样东西
其中,Access Token 你需要从 Vercel 后台的 Tokens 页面获取。
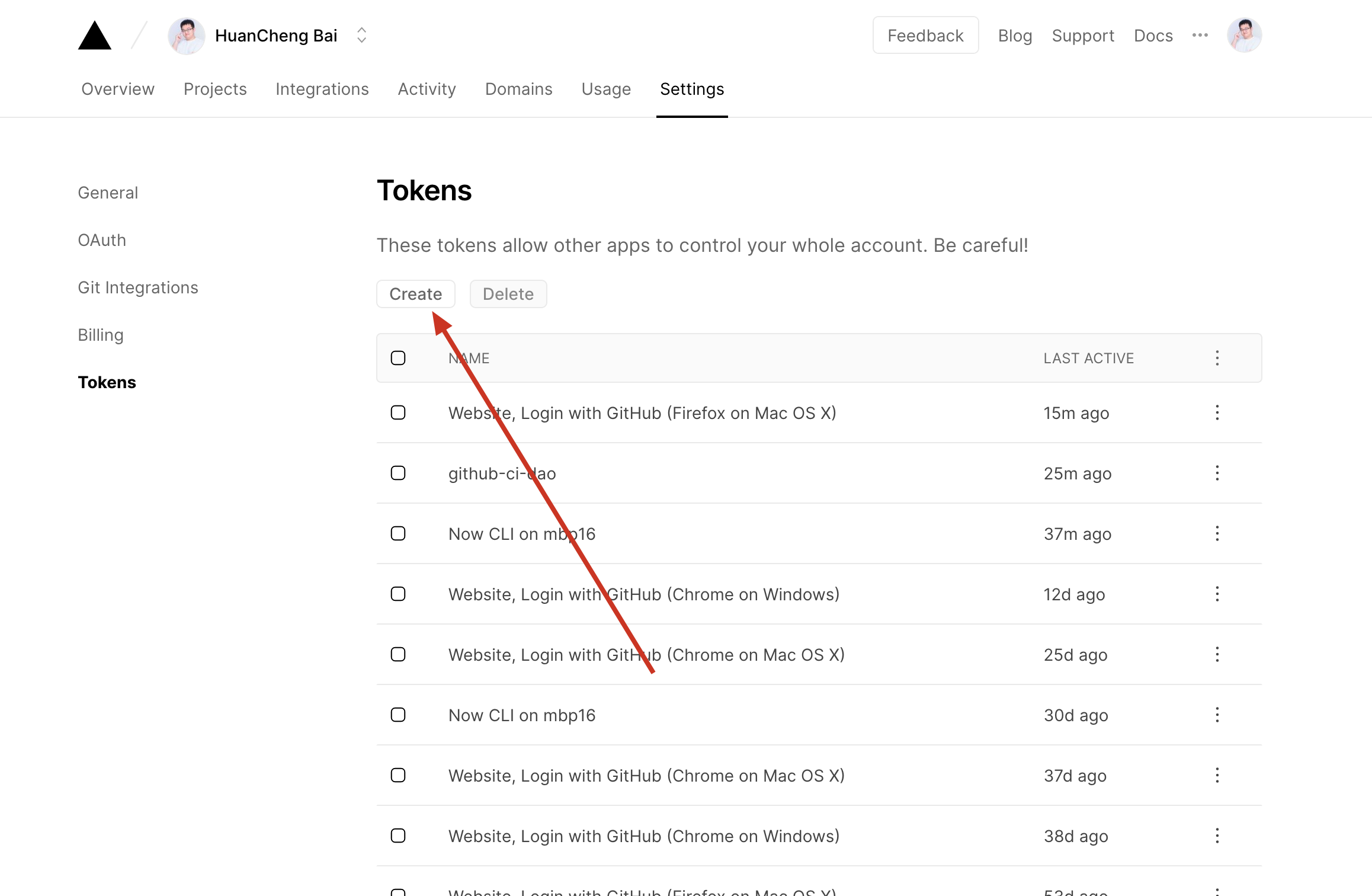
而 Org ID 则可以从你的项目中的 .vercel/project.json 中获取。你会获得类似下面这样的内容,其中的 OrgID 就是你在 Vercel 上的 ID ,而 Project ID 就是对应的项目 ID。
{"orgId":"r359XAnYONVAmiXtdxZ22A2E","projectId":"Qma3GdwoiAfJSsbsSydBgaCDh8LJj6wTWvvqpUwrN6J2F3"}准备好了这三项以后,就可以进入到下一个环节,配置 Action Secret 了。
Github Action 提供了 Secret 的机制,用来让你保存哪些安全密钥,避免直接写在 Action File 中,出现泄漏的可能。
打开你的项目的 Settings – Secrets 页面
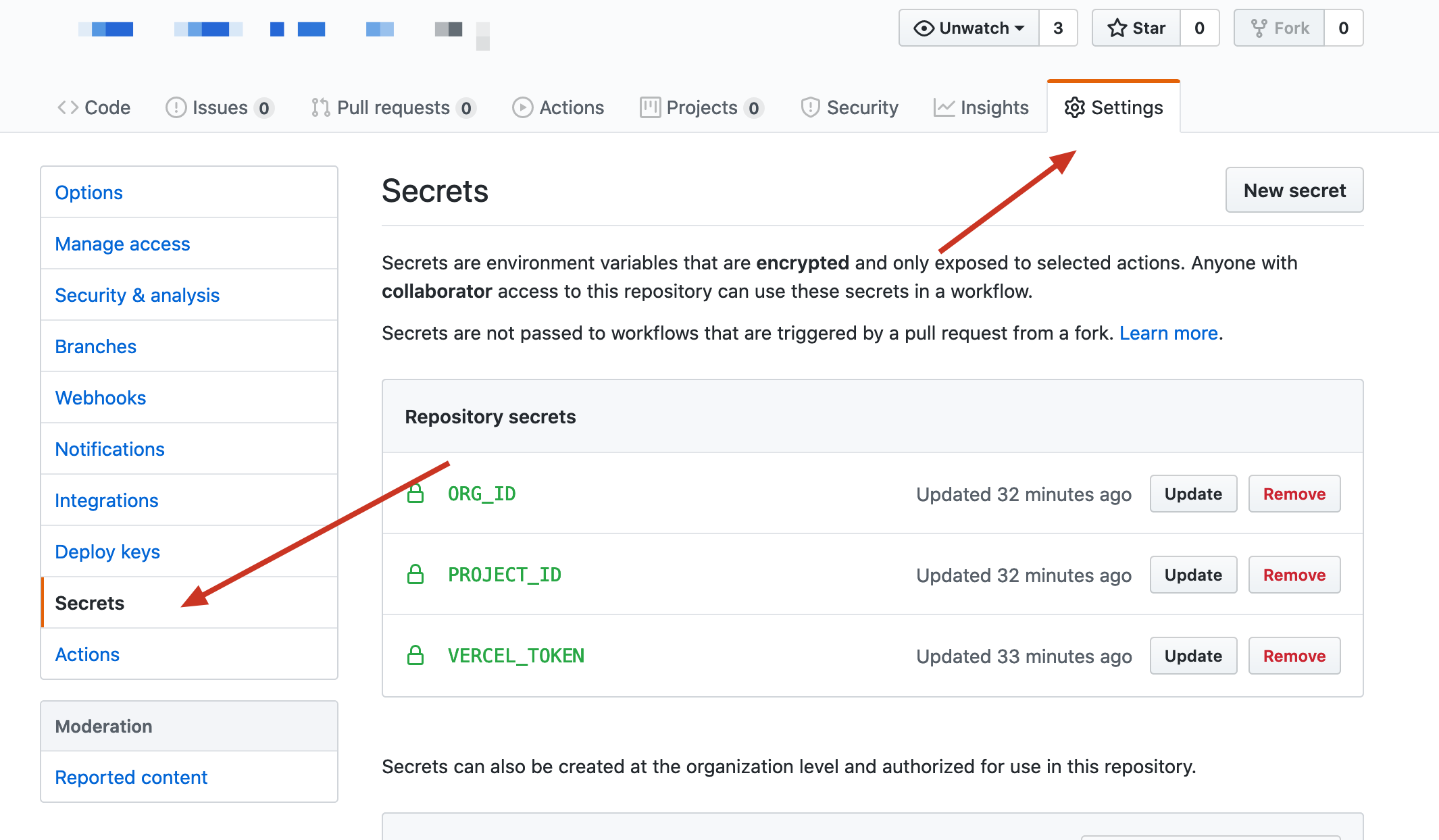
在这里你可以新增 Secret ,你需要新增三个 Secret ,分别是
ORG_ID: 填写你从 .vercel/project.json 中获取到的 orgId;PROJECT_ID:填写你从 .vercel/project.json 中获取到的 projectId;VERCEL_TOKEN:填写你从 Vercel 后台生成的 Token。这样,就配置好了 Secret ,接下来就可以在你的项目中加入 a、Action 配置文件,完成项目的配置。
根据 Github 的规范,你需要将你的 Action 配置文件放置在项目根目录的 .github/workflows/xxx.yml 文件中,其中 xxx 是你的 Action 名,比如叫 vercel.yml 。
这里我使用的是 ngduc 写的 vercel-deploy-action
按照路径创建好 vercel.yml 文件,然后在其中加入如下代码
name: deploy website
on:
push:
branches:
- master
pull_request:
branches:
- master
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- uses: ngduc/vercel-deploy-action@master
with:
vercel-cli: vercel
vercel-token: ${{ secrets.VERCEL_TOKEN }}
vercel-org-id: ${{ secrets.ORG_ID}}
vercel-project-id: ${{ secrets.PROJECT_ID}}
github-token: ${{ secrets.GITHUB_TOKEN }}粘贴进去以后,将 vercel.yml 添加到 git 控制中,并提交到 Github 上,就可以实现触发 Vercel 了。
虽然 Vercel 本身不能免费提供 Organization 的支持,但是我们可以通过一些小的技巧,绕过其官方的配置。对于一些只是将 Vercel 配置为开发者预览的场景下来说,还是足够的。
但如果你希望将 Vercel 配置为生产环境,那么 Teams Plan 可以提供的更多的权限控制,会是你需要的,买一个,也不贵,是吧?


hexo-generator-podcasts 是我近期开发的一款 Hexo 的播客生成器插件,hexo-generatro-podcast 可以帮助你在你的 Hexo 博客中加入播客的功能,你可以通过简单的配置,在自己的博客中加入播客的配置,轻松上架播客。
不仅如此,如果你需要部署多个播客,也可以直接借助这个插件,在一个站点中部署多个播客,特别适用于一些大型的播客组织,可以在一个站点同事部署多个播客。
如果你感兴趣,不妨去试试看: https://github.com/bestony/hexo-generator-podcasts/
此外,我自己的播客生产力维基,就是使用这个插件构建的。

$this->need("xxx");
// 提供插件的Hook
$this->footer();可以创建 category 、page目录,根据名字自动加载不同的模板
文章为post目录,根据ID自动加载不同的模板
有用的themeFields

define('__TYPECHO_DEBUG__',true);
打开 Debug 模式
define('__TYPECHO_SECURE__', true);强制SSL
define('__TYPECHO_GRAVATAR_PREFIX__', 'https://myavatar.com/avatar');
Avatar 前缀
最近我在开发一个 Hexo 插件,在开发的过程中,遇到了一些小的问题:插件的代码发生了修改,但运行hexo 的时候却没有实时刷新出来。
在对代码进行分析后发现,hexo 的 tag filter 的结果会缓存在数据库中,由于缓存了,所以我使用的 generator ,所以也会被缓存。
在预览前,删除 db.json 即可让 hexo 重新开始生成
为了方便,我在 npm 的 scripts 中加入了一个自定义的配置
{
...
"scripts":{
...
"s": "rm db.json && hexo server"
...
}
...
}最近在参与 WavPub 的开发,在开发的过程中,需要调整 XML 的结构,因此,需要为一些字段加入 CDATA 的支持。
在阅读了 eduncan911/podcast 中的代码后发现,这个包在生成 XML 的时候,使用的是 Golang 核心库中的 encoding/xml 包,而这个包在使用的时候有一个问题,你可以给其字段加入 ,cdata 来完成加入 cdata 的标签,但问题在于,他的实现是,在你的字段外部加标签,而不是内部加标签。举个例子来说,就是,如果你定义了字段为 xml:”category,cdata” 你得到的会是
<![CDATA[ somecode ]]>而非我们想要的
<category> <![CDATA[ xxx ]]> </category>想要解决这个问题,就需要你在你的字段中实现一层包裹,在其自动生成的 CDATA 外层加入一层 XML ,这样就可以实现我们想要的效果,比如说我上面的效果可以通过定义一个新的 Description 的 Struct 来实现
package podcast
import "encoding/xml"
// Description represents text inputs.
type Description struct {
XMLName xml.Name `xml:"description"`
Text string `xml:",cdata"`
}然后,再在需要的地方,加入相应的引用就好
type Podcast struct {
XMLName xml.Name `xml:"channel"`
...
Description *Description
...
}在某些场景下,需要根据给定值,返回一批特定的结果,在这种情况下,需要返回切片中的某一个特定的值。
package main
import (
"fmt"
"math/rand"
"time"
)
func main() {
userAgentSlice := []string{
"Podcasts/1430.46+CFNetwork/1125.2+Darwin/19.4.0",
"Spotify/1.0",
"PocketCasts/1.0+(Pocket+Casts+Feed+Parser;++http://pocketcasts.com/)",
"iTMS",
"AirPodcasts/1440.4+CFNetwork/1126+Darwin/19.5.0",
"Tentacles,+Like+iTunes",
}
rand.Seed(time.Now().Unix())
fmt.Println(userAgentSlice[rand.Intn(len(userAgentSlice))])
}
两会期间,各种工具的效果都会大幅度下降。在这种情况下,作为翻译组,想要好好干活也是挺麻烦的,于是,便写了一些简单的工具,来解决这种特殊情况下的尴尬问题。
在翻译组,我们有专门的机器来负责内容抓取 & 转化成为 markdown,但同时,文章中会有一些图片,种种原因,会导致这些图片无法访问。在翻译的时候,我们需要对这些图片进行下载,在这种情况下,就会很麻烦。我们需要一个更加简单的方式,来完成文件的下载。
Simple Proxy 就是来解决这个问题的,他可以让你很方便的完成外网的文件下载(当然,前提是你的 Proxy Server 可以访问到这个文件。
使用方法:
在实际的使用过程中,我给你的建议是,
这样可以让你的使用体验达到最佳。
参考:https://github.com/bestony/simple-proxy
Simple Proxy 的代码十分简单,加入了大量的注释,也不过 51 行。
最为核心的代码源自于其中的
res.set({
'Content-Disposition': `attachment; filename=${filename}`
})这段代码的用户是为返回值设定 Header ,其中用到的 Header Content-Disposition 是 HTTP 协议早期定义的 Header 规范。
如果你将其值设置为 inline,其内容将会直接展示在界面中;
其值设置为 attachment 则可以启动系统浏览器自带的下载功能。
其值中加入 filename 则可以更进一步,在下载时,指定下载的名称,在本次的项目中,就借助了这样的功能,让下载的文件名不发生改变。
Podcast 依赖于 RSS Feed ,因此,可以参考一些官方的页面了解 Podcast Feed 的格式。
[[xxx]] 是目前比较常见的 backlink ,特别是各种笔记应用。
在转化格式的时候,如果你需要将 [[xxx]] 替换为传统的 markdown 格式,这个时候你可以借助一个简单的 sed 命令来完成这些工作
使用时把 test.md 替换为源文件,output.md 替换为导出的文件
sed -E "s/\[{2}(.*)\]{2}/[\\1](\\1)/g" test.md >> output.md这段代码使用了 sed 来完成修改,其中使用正则表达式替换 backlink 。
说起正则表达式,在我高中的时候,我误以为正则表达式是一种数学表达式,还跑去问了问我的高中数学老师,老师理所当然的不知道。
我自己在测试正则表达式的时候,会用到的工具主要是 RegExr ,不过最近发现有人部署了一个速度更快的 RegExr-CN,有需要的同学可以试试看
因为 -i 的话,怕把文件搞坏而没有备份,用管道虽然麻烦了点,但至少不修改源文件,安全一些。
2020.05.24 fix some layout error