
总也抢不到的红包
一切都源自于一个红包,下午,朋友发消息给我说,让我领个红包。
打开后,看到红包,我不禁笑了。想我国家普通话水平等级测试一级乙等的水平,岂会怕一个小小的语音口令?
我清了清嗓子,以纯正的“播音腔”,念了“四十是四十,十四是屎拾”,小程序冷笑了一声,返回给我了个“再接再厉,再录一次”。

我以为是自己没说好,站起身,气沉丹田,再次念了一次“四十是四十,十四是屎拾”,旁人纷纷对我传来了异样的眼光…..然而异样的眼光也并没有
我灰溜溜的走出房间,找了一处无人的地方,一次次的尝试去读“四十是四十,十四是屎拾”。然而努力是没有结果的,每次都是武功而返。

“我要说口令”背后的秘密
既然无法抢到红包,气急败坏的我开始想,为什么我这么纯正的普通话,还抢不到红包?
作为一个普通话一乙的北方人,如果我都领不了红包,岂不是只有一甲的播音员们才能抢到?问题肯定不在此。于是,我开始动用我身为程序员的本能,开始分析小程序背后的技术。
终于,我想到了,它之所以能够做到读对口令才能抢到红包,完全是依赖于背后的一项技术——“语音识别”
什么是语音识别?
语音识别背后有非常多的技术,我这里尽量简单的给你说明什么是语音识别。
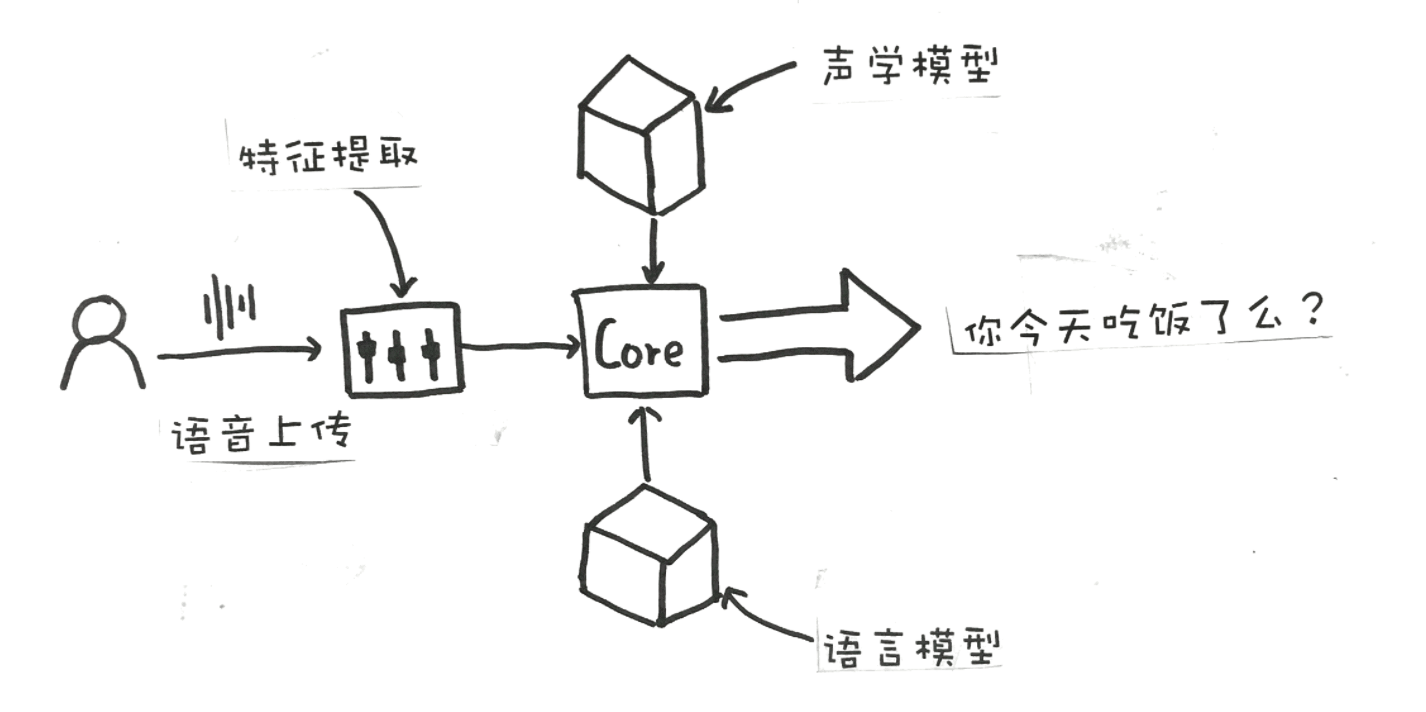
首先,用户在 App 中按下按钮,录制语音,然后 App 会将音频上传到后台的服务器,后台的服务器对声音进行特征提取,传递给下个阶段的处理器,这个时候,我们的声音信号已经由声音信号转变为处理后的特征信号。
然后处理器再通过接入 “声学模型”,来获取不同的特征信号可能代表的字词;再由“语言模型”,实现对所有可能字词的选择,得出最可能的结果。
最终,经过一系列的处理,我们说话的一段语音信号,就变成了一句话 “你今天吃饭了么?”
英语流利说的语音识别
英语流利说的语音识别功能是非常厉害的,就如其广告中所说“会打分的人工智能英语老师”,英语流利说的依仗,便是其比别人更加优秀的”声学模型“和”语言模型“
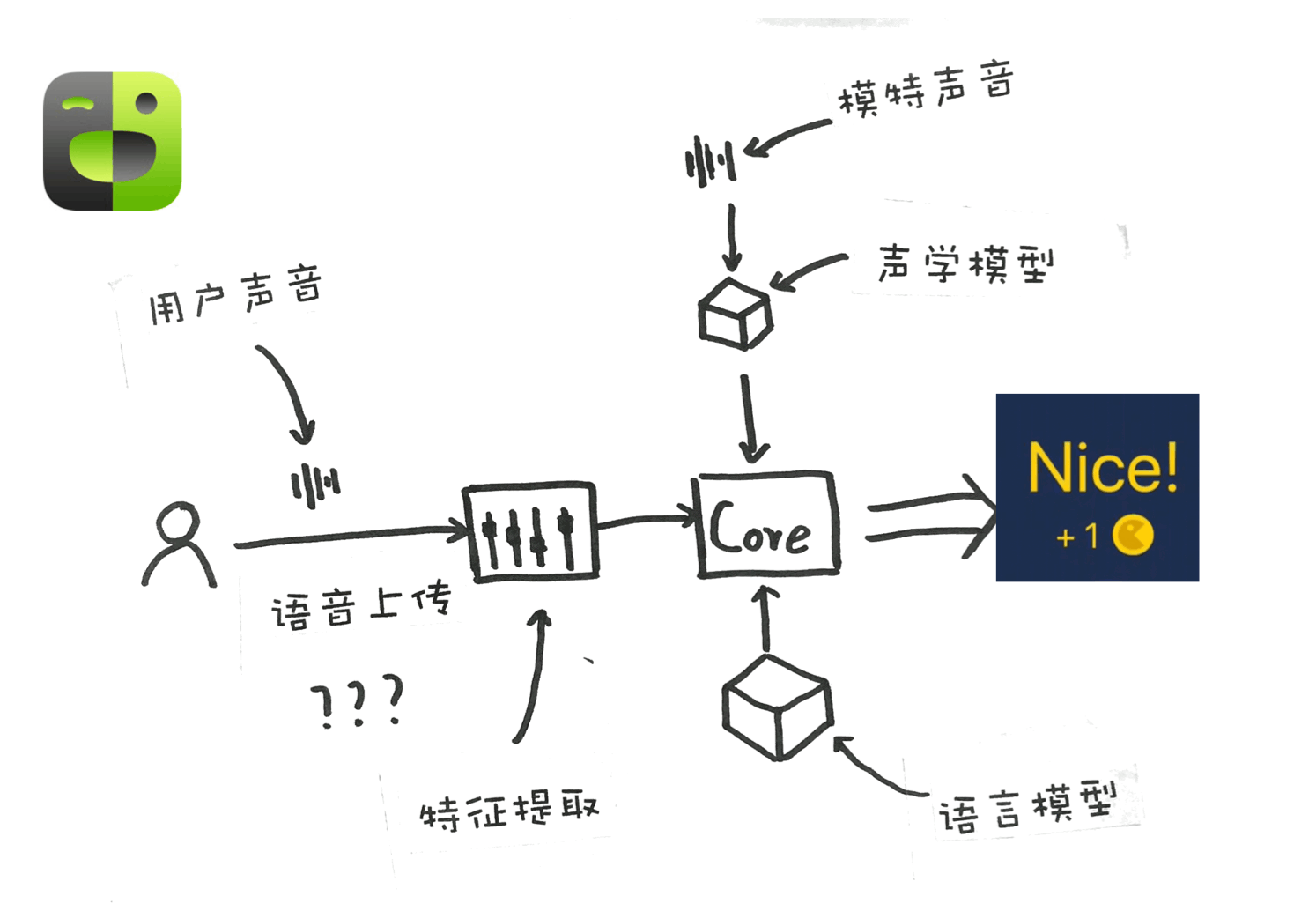
学员在手机上录音,录音经过上传,到云端进行特征提取,再由“模特声音训练过”的“声学模型”进行处理(这里的模特声音训练过非常重要,训练材料的不同会导致模型的天差地别),声学模型处理过后,文字会传递给语言模型,组合成句。在完成两处处理后,对声音信号和文字信号进行打分,如果你的准确率比较高,你就能够获得一个Nice!
语音上传部分我打了问号,是因为流利说本身也有离线打分引擎,所以可能我们的语音没有上传到云端,在本地就直接进行处理了。
更细致的信息你可以到 「英语流利说」是如何进行比对评分的? – 林晖的回答 – 知乎去看,林晖先生解释的很细致。
“我要说口令” 如何实现读口令抢红包的功能?
由于“我要说口令”小程序本身的功能要比英语流利说更为简单一些,不需要进行特殊模型训练,可以借助一些云计算服务商提供的 API 来实现功能。这里,我们拿“阿里云 ET 智能语音交互”服务 来举例。
此处仅代表我个人针对“我要说口令”小程序的分析,不代表其官方架构。
小程序在手机上进行录音,然后将录音上传至开发者的服务器,服务器上的后台程序再将声音信号通过 API 传递给** 阿里云 ET 智能语音交互**,并调用其中的 智能语音识别接口,接口对语音信号进行处理后,返回识别的文字,比如在刚刚那个红包中,识别出来的文字是“四十是四十是四是屎拾”。开发者的服务器在受到服务器传回的文字后,和发红包的人设置的文字对比,看看两个文字是否相同。如果文字相同,就说明读对了,用户就可以拿到红包;如果文字不同,就要告诉用户“再接再励”了。
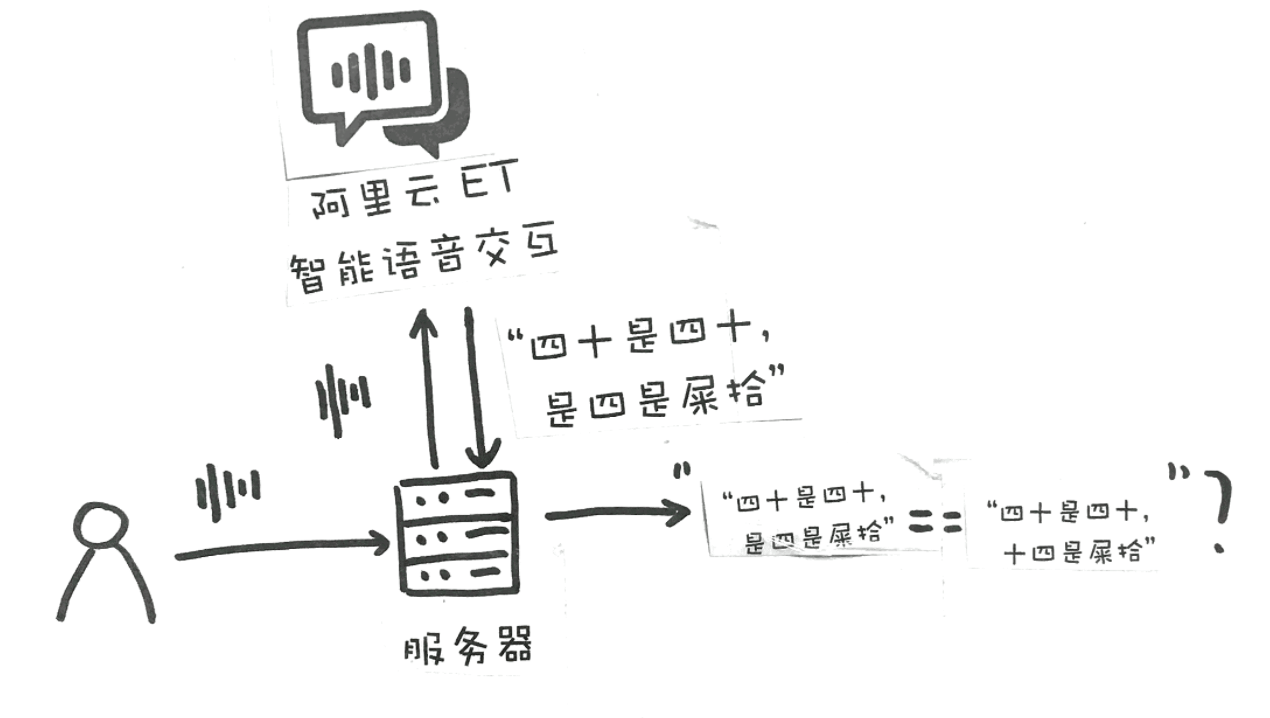
当然,实际上在对比的标准中可能不会这么简单,因为在这种情况下,声学模型和语言模型识别出来的文字可能会非常奇葩,用户能够匹配上设置的文字的可能性就会非常小,这时,程序员可能就会在这方面设置一个“冗余度”,如果内容中有80%的文字是对的上,就能拿到红包。
这个红包,我不要了!
想到这里,我不禁悲从中来,由于“声学模型”和“语言模型”的性能,计算我读的再好,可能也无法被很完美的识别出来。特别是这种几乎是无序的内容,语言模型根本无法很好的处理,我总是抢不到红包也是正常的了。以我的运气,这辈子怕是都抢不到语音红包了,我还是去群里抢普通运气红包吧!
不过,虽然我不能抢红包,但是我可以去做一个抢红包的小程序!有了“阿里云 ET 智能语音交互”,无需自主建立语音识别的系统,轻松实现语音识别!
阿里云智能语音交互地址:https://data.aliyun.com/product/nls
写在最后:
谁认识阿里云的语音交互的运营小姐姐,帮忙问问,我这么卖力,给我个鸡腿吃好不好!