let writer = new ExcelWriter({
sheets: [{
name: 'Test Sheet',
key: 'tests',
headers: [{
name: 'Test Name',
key: 'name'
}, {
name: 'Test Coverage',
key: 'testValue',
default: 0
}]
}]
});
let dataPromises = inputs.map((input) => {
// 'tests' is the key of the sheet. That is used
// to add data to only the Test Sheet
writer.addData('tests', input);
});
Promise.all(dataPromises)
.then(() => {
return writer.save();
})
.then((stream) => {
stream.pipe(fs.createWriteStream('data.xlsx'));
});
var Database = require('warehouse');
var db = new Database();
var Post = db.model('posts', {
title: String,
created: {type: Date, default: Date.now}
});
Post.insert({
title: 'Hello world'
}).then(function(post){
console.log(post);
});
如果你需要将这些数据保存为一个单独的文件,只需要修改初始化的参数,并执行 save 方法,就可以将 JSON 导出到指定的文件中
var db = new Database({
path: "./test.json", // 将数据存储在 test.json 当中
});
db.save();
类似的,如果数据已经构建好了,也只需要执行 load 方法,就可以加载数据。
var db = new Database({
path: "./test.json", // 将数据存储在 test.json 当中
});
db.load();
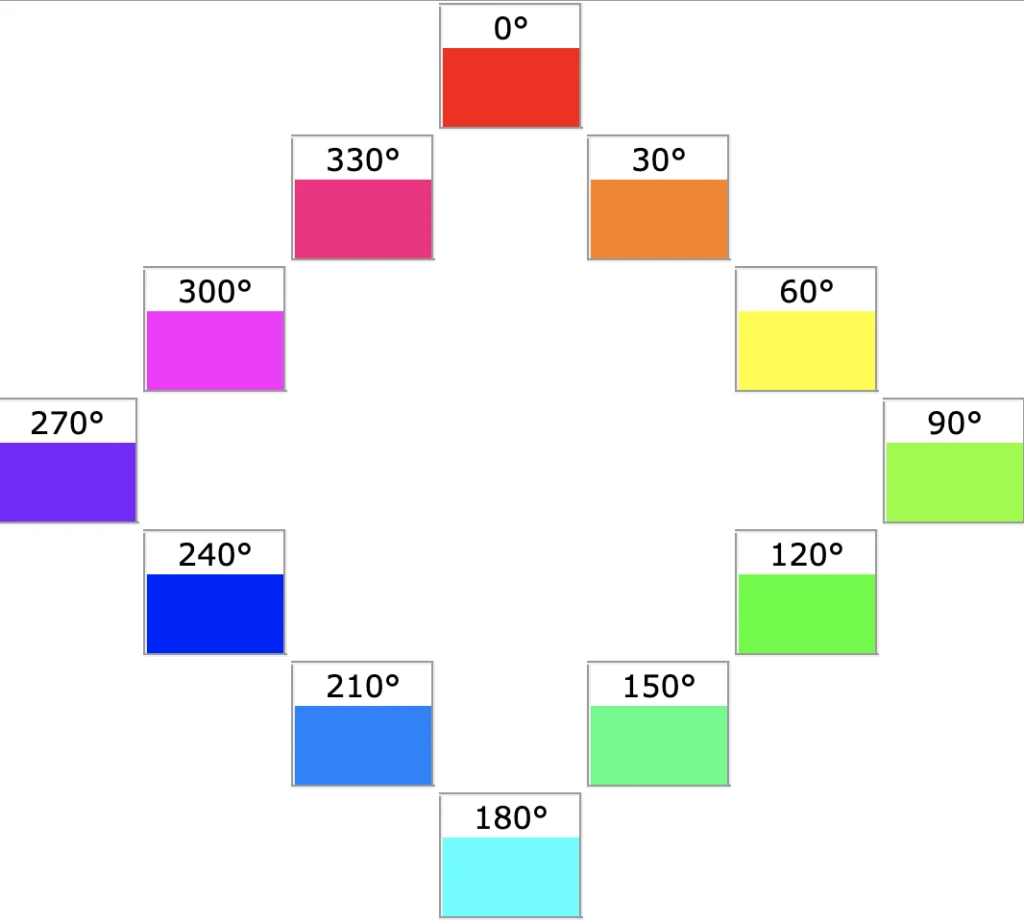
function rgbToHsl(r, g, b) {
r /= 255, g /= 255, b /= 255;
var max = Math.max(r, g, b),
min = Math.min(r, g, b);
var h, s, l = (max + min) / 2;
if (max == min) {
h = s = 0; // achromatic
} else {
var d = max - min;
s = l > 0.5 ? d / (2 - max - min) : d / (max + min);
switch (max) {
case r:
h = (g - b) / d + (g < b ? 6 : 0);
break;
case g:
h = (b - r) / d + 2;
break;
case b:
h = (r - g) / d + 4;
break;
}
h /= 6;
}
return [h, s, l];
}